Classification Evaluation Metrics
in Machine Learning on Strategy
Precision & Recall

Precision
머신러닝에서 분류 작업을 할 때, Precision은 Positive로 분류된 element 중 실제 Positive element의 비율이다.
In a classification task, the Precision for a class is the number of true positives
divided by the total number of elements labelled as belonging to the positive class
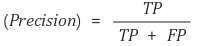
Recall
Recall은 실제 Positive class 중 positive로 올바르게 분류된 것의 비율이다. Recall is defined as the number of true positives
divided by the total number of elements that actually belong to the positive class
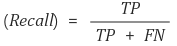
Precision-Recall Trade-off
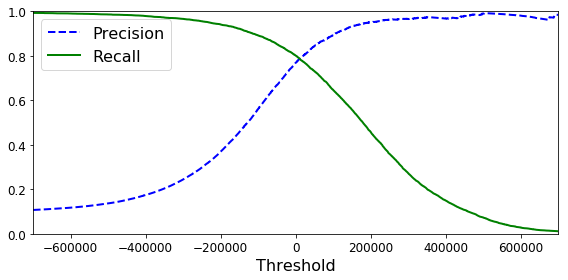
이상적인 시나리오는 Precision과 Recall이 둘 다 1.0인 경우이다.
하지만 대부분의 상황에서 이 두가지가 모두 만점을 받게 하긴 어렵다.
왜냐하면 대부분의 데이터셋에는 noise가 존재하기 때문에 완벽하게 분리하기란 어렵다. 따라서 모델은 Threshold를 사용하여 Precision과 Recall의 trade-off를 반영하여 선택되어야 한다.
Accuracy
Precision과 Recall은 Positive 상황만 고려한다. 하지만 False 상황 또한 고려할 수 있는 요소이다.
Accuracy는 False 상황을 고려하여 계산된다. 이를 통해 False와 True가 모두 고려된 평가를 할 수 있다. 
Accuracy는 가장 직관적으로 모델의 성능을 나타내는 지표이다.
그러나, Bias of Domain이 고려되어야 하므로 이를 보완하는 지표가 필요하다.
만약 입력 데이터가 불균형 데이터라면 Accuracy는 올바른 평가를 내지 못한다.
즉, 데이터가 균형적일때 Accuracy는 좋은 선택이 된다.
F1 Score
F1 Score는 Precision과 Recall의 harmonic mean(조화평균)이다. 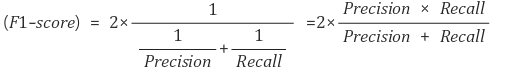
F1 Score는 불균형 데이터에서도 준수한 성능 측정을 보여준다. 왜냐하면 사용되는 조화평균이 Precision과 Recall 사이의 불균형을 잘 보정해주기 때문이다.

My CS, ML Study Journal